







스마트폰 얼굴 인식부터 자율주행차까지 쓰이는 인공지능(AI)은 내부 구조가 외부에 드러나지 않는 '블랙박스'로 보호돼 왔습니다.
이런 가운데 한국과학기술원(KAIST)을 비롯한 국제 공동 연구진은 벽 너머에서 AI의 '설계도'를 훔쳐볼 수 있는 새로운 보안 위협을 밝혀냈습니다. 이와 함께 대응 기술도 함께 제시했습니다.
KAIST 전산학부 한준 교수 연구팀은 싱가포르국립대(NUS), 중국 저장대(Zhejiang University)와의 공동 연구를 통해 소형 안테나만으로 원거리에서 AI 모델 구조를 탈취할 수 있는 공격 시스템 '모델스파이(ModelSpy)'를 개발했다고 31일 밝혔습니다.
이 기술은 도청 장치처럼 AI가 작동할 때 발생하는 미세한 신호를 포착해 내부 구조를 분석하는 방식입니다. 연구팀은 인공지능 연산을 담당하는 그래픽처리장치(GPU)에서 발생하는 전자기파에 주목했습니다.
AI가 복잡한 연산을 수행할 때 GPU에서는 미세한 전자기 신호가 발생하는데, 연구팀은 이 신호의 패턴을 분석해 모델의 층 구성과 세부 설정값을 복원하는 데 성공했습니다.
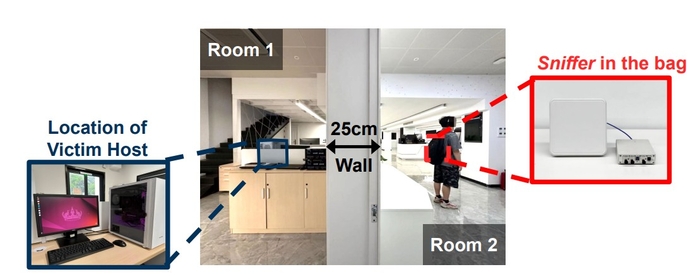
실험 결과, 최신 GPU 5종을 대상으로 벽 너머나 최대 6m 거리에서도 AI 모델 구조를 높은 정확도로 파악할 수 있었습니다. 특히 딥러닝 모델의 핵심 구조인 레이어를 최대 97.6%의 정확도로 추정했습니다.
이번 기술은 기존 해킹처럼 서버에 직접 침투하거나 악성코드를 설치하지 않아도, 가방에 넣을 수 있는 소형 안테나만으로 공격이 가능하다는 점에서 큰 보안 위협으로 평가됩니다.
연구팀은 이러한 기술이 악용될 경우 기업의 핵심 AI 자산이 외부로 유출될 수 있다고 보고, 전자기파 교란이나 연산 난독화 등 대응 기술도 함께 제시했습니다. 단순한 공격 시연을 넘어 현실적인 방어 방안을 제시했다는 점에서 책임 있는 보안 연구 사례로 꼽힙니다.
이번 연구는 KAIST 전산학부 한준 교수가 공동 교신저자로 참여했으며, 컴퓨터 보안 분야 최고 권위 학술대회인 'NDSS(Network and Distributed System Security Symposium) 2026'에서 발표됐습니다. 아울러 연구의 혁신성을 인정받아 최우수 논문상도 수상했습니다.
최성훈 기자 csh87@etnews.com